尝试一下vibe coding
简单玩了下最近很火的 vibe coding。
根据API做了个模型playground,没用什么工作流,就是古法聊天。
界面如下:
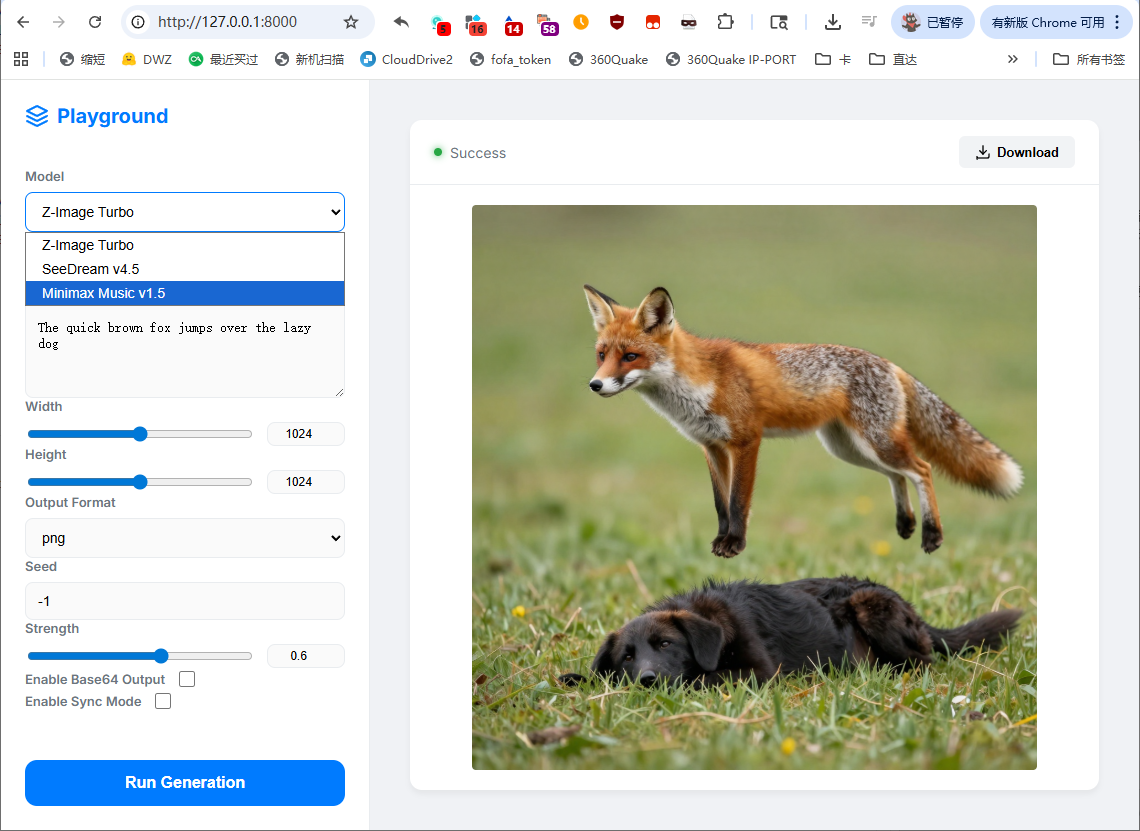
在 Antigravity 中使用 Gemini 3 flash 完成,一共就四轮对话,还挺好玩的:完整的 prompt。
简单玩了下最近很火的 vibe coding。
根据API做了个模型playground,没用什么工作流,就是古法聊天。
界面如下:
在 Antigravity 中使用 Gemini 3 flash 完成,一共就四轮对话,还挺好玩的:完整的 prompt。
很久没去 HuggingFace,发现又多了一些第三方 LLM 接口,并且特地做了一个支持直接调用的 LLM 列表。可以看到,最全的依然是 novita,其他基本是凑数的。
不过,最大的发现是,图片生成增加了一家供应商:WaveSpeed。相比不能试用的 fal 和审核很严的 Replicate,WaveSpeed 可以说是可用性极高。
配合以前的一个小技巧——HuggingFace 实际支持第三方接口的所有模型(包括不在 HuggingFace 上的闭源模型),我们还可以 router 调用 Nano-Banana。
还不止于此,只要接口统一,其他任何模型,甚至是音乐生成模型,也能调用。
# pip install wavespeed
from wavespeed import Client
hf_key = YOUR_HF_KEY
hf_base_url = "https://router.huggingface.co/wavespeed"
def text_to_music(prompt, lyrics, model):
client = Client(api_key=hf_key, base_url=hf_base_url)
output = client.run(
model,
{
"bitrate": 256000,
"lyrics": lyrics,
"prompt": prompt,
"sample_rate": 44100
},
timeout=36000.0,
poll_interval=1.0,
enable_sync_mode=False,
)
return output["outputs"][0]
model = "minimax/music-02"
prompt = "一首中式古典歌曲,由古筝弹奏,由轻柔的男声演唱"
lyrics = "窗前明月光,\n疑似地上霜。\n举头望明月,\n低头思故乡。"
print(text_to_music(prompt, lyrics, model))
可以说,HuggingFace 的 router 就是真是个 router。实践中,并不是所有的供应商都能随意跨模型,例如:不能用 replicate 的 LLM;调 novita 非 LLM 服务结果会截断。这不是因为 HuggingFace 做了限制,而是 router 这块代码够烂。可能这块是 vibe coding出来的?
由于需要 HTTPS,稍微找了一下手动生成方案,目前最方便似乎是PunchSalad。每次生成 Let's Encrypt 可以提供90天的免费证书。
据我了解,AMH、SSL For Free 也有申请证书的服务,不过还要注册,不如 PunchSalad 方便。
之所以需要手动生成,是因为之前在「支付宝-小程序云」上托管了几个静态页面:前情提要。这个「小程序云」自然是无法自动续期证书的,只能手动。顺带一提,这个空间不支持通配符证书……
之前,我想用自己的域名做短链,从而避免烂大街的域名被微信、QQ 限制。试用了国内的服务,凡是免费层级都不让用 HTTPS,而且必在跳转时随机插广告(借口被运营商劫持,其实根本就是服务商自己搞鬼)。
后来退而求其次,找到了替代品:搜狐快码。直接购买的门槛比较高,通过好单库生成,可以用多少充多少,性价比比较高。一些国内企业建立的 Yourls 服务也挺好用,因为过于小众,又有备案,不容易被限制。
至于静态托管的问题,似乎今年阿里云的免费 ESA 也上线了,也许托管到 Github Pages 再套个 CDN 更省事,有空再试试看。
最近突然想玩点赛车游戏,稍微看了一下,好家伙一个个都动辄几十G,瞬间就不想玩了。
突然想起来当年有个单机版的跑跑卡丁车,没想到现在已经进化到可以玩最新地图了,还可以AI填充。
启动器:yanygm@github/Launcher_V2
客户端:brownsugar@github/popkart-client-archive
3个G还是可以的,还是个绿色版~
开得一塌糊涂,只能玩玩简单AI,还不如以前小板车跑得快(扶额)
最近在试唱英文歌,发现市面上的K歌App都不好用,最终动用了视频剪辑软件。
视频剪辑软件的优点:
J K L预览倍速。我把原曲调成了0.5倍速,通过双击L播放,J快退,很方便。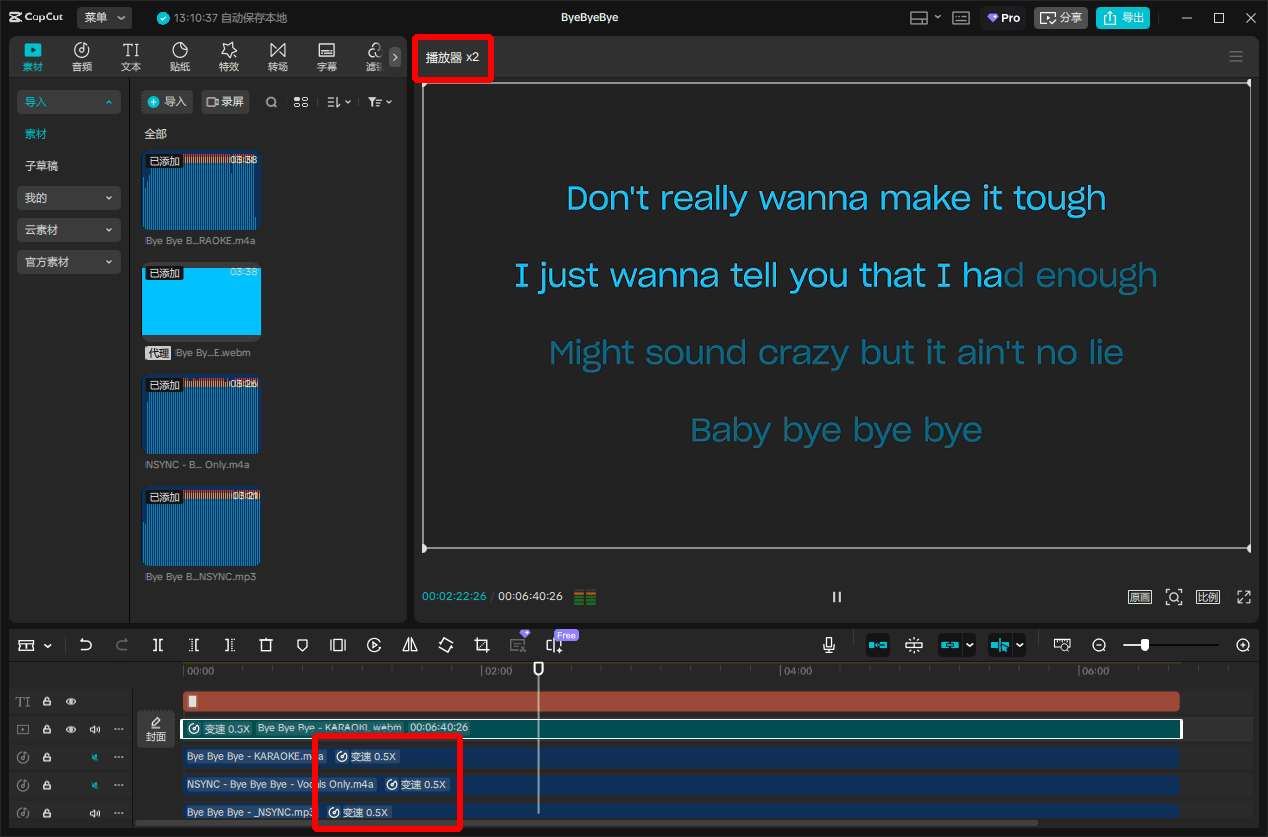
剪映的优势:
其他方案的问题:
我习惯使用Windows睡眠,很少关机。但是系统总是越用越卡,最终不得不重启。这个情况持续了很长一段时间,64G的内存基本上只能支撑1-2周,并且一直找不到原因。
最近,这个问题终于彻底解决。流程和和这篇《win10非分页缓冲池占用过大的解决方法》几乎一致。
内存泄漏的情况千奇百怪,总有前人踩过坑。然而,往往要已经定位到问题,才能搜到对应的文章,属于是马后炮了。所以我姑且记录一下自己的流程。
首先,查了一些常见的系统泄漏情况,关闭了微软输入法,无效。
接着,用Process Explorer查找问题,没有异常进程。
继续研究,有一些用户提到显卡驱动有内存泄漏,如果是这种驱动级泄漏,Process Explorer是找不到的。
ChatGPT的解释:
Process Explorer 本身主要用于查看和分析用户模式下的进程和线程活动,比如 CPU、内存、句柄和 DLL 的使用情况。
它不直接提供定位驱动级别内存泄漏的功能,因为驱动程序运行在内核模式下,而 Process Explorer 主要关注用户模式的行为。系统开机一段时间后,用PoolMonX查驱动,Diff排序,此时FMfn攀升到第一位。
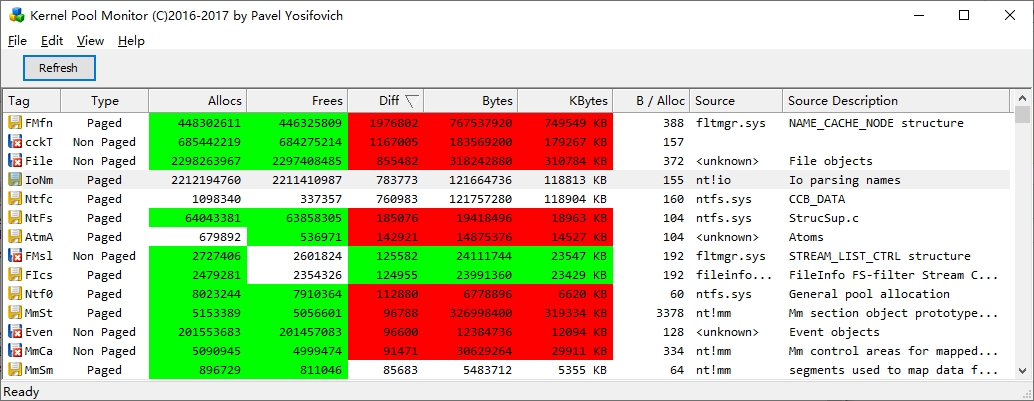
按照网上的说法,应该要查Non Paged,不过我这里显示是Paged。Diff代表申请和释放内存的差值,如果数字太大,代表没释放的内存在堆积。
C:\WINDOWS\system32>fltmc 筛选器名称 数字实例 高度 框架 ------------------------------ ------------- ------------ ----- cbfs6 <过时> bindflt 1 409800 0 lrtp 17 389170 0 sysdiag 7 324600 0 storqosflt 0 244000 0 wcifs 1 189900 0 CldFlt 10 180451 0 FileCrypt 1 141100 0 luafv 1 135000 0 npsvctrig 1 46000 0 Wof 13 40700 0 FileInfo 17 40500 0
问一下ChatGPT这都是些什么:
cbfs6:通常与 Callback File System 相关,这是一个用于开发虚拟文件系统的第三方工具。
bindflt:Windows 内置驱动,绑定筛选器驱动程序,用于文件系统绑定操作。
lrtp:未知,这个名称不像常见的系统驱动,可能需要更深入的检查。
sysdiag:未知,名称看似与系统诊断有关,但没有明确的 Windows 系统驱动使用这个名称。
storqosflt:Windows 内置驱动,存储质量服务过滤器,与存储设备的性能管理相关。
wcifs:Windows 内置驱动,Windows 容器隔离文件系统,支持容器化文件操作。
CldFlt:Windows 内置驱动,Cloud Files Mini Filter Driver,用于 OneDrive 等云存储服务的文件占位符功能。
FileCrypt:Windows 内置驱动,文件加密驱动,处理文件级别的加密操作。
luafv:Windows 内置驱动,用户账户控制虚拟化,用于兼容旧软件的 UAC 虚拟化支持。
npsvctrig:Windows 内置驱动,服务触发器提供程序,用于触发基于网络事件的服务操作。
Wof:Windows 内置驱动,Windows Overlay Filter,用于处理压缩和解压缩的文件存取操作(如 NTFS 压缩或 WIM 挂载)。
FileInfo:Windows 内置驱动,文件信息筛选器,用于收集文件元数据,常用于安全审计。有两个未知,其中sysdiag是火绒。继续定位lrtp.sys:
C:\>findstr /m /l /s lrtp *.sys Program Files (x86)\Lenovo\LenovoInternetSoftwareFramework\lrtp.sys FINDSTR: 无法打开 swapfile.sys Windows\System32\drivers\lrtp.sys
原来是联想的东西,搜了一下,这个驱动属于老版本的管家残留,新版本已经换驱动了,所以无法通过装新版再卸载来解决。网上大概有三四篇文章提到这个驱动存在内存泄漏,包括开头提到的那篇。
总之,可以暴力删除,也可以用这篇文章末尾的批处理:《联想电脑管家卸载残留完整分析》
至此,系统内存泄漏问题解决。
题外话,通过这次排查,我才知道任务管理器的使用中内存根本就是文字游戏,备用内存更是毫无意义的数字。
使用中代表这部分物理内存正在使用,但真正不能释放的部分是已提交。打个比方,有人预订了酒店,但他不一定入住,酒店没办法把这些空房安排给其他客人。预订就是已提交,使用中就是实际入住,有人占着茅坑不拉屎,不等于茅坑能再次分配。
备用就更没有意义,这个数字等于物理内存总量减去使用中。其中既有不能释放的申请,又包括了可以释放的缓存。这个名称给人一种”这些内存在必要时可以分配给其他应用“的错觉,我不知道计算这个的意义是什么。
内存释放工具主要就是转移这部分内存,这些数据被暂时移到硬盘后,又会被系统慢慢加载回来,所以解决不了内存爆炸后的卡顿的问题,最多只能缓解几分钟。而频繁清理,硬盘压力会变大,只会使系统更加卡顿。
一个典型的例子是Photoshop。在Photoshop中关闭文件后,这部分内存并不会被释放。官方的解释是,软件为了不反复申请内存,所以不释放内存,而是留着给未来的操作重用。实际上,这就是典型的内存泄漏,而且这些内存根本不像官方说的那样会重用。
如果用内存清理软件清理,这些物理内存占用快速下降,但是观察进程管理器,可以看到内存很快又会攀升,并且磁盘忙碌。整个过程最多5分钟,已提交的数字不会变化,等于是这些内存去分页文件逛了一圈。这时候,唯一能做的就是重启Photoshop。
驱动级泄漏最麻烦的地方在于,如果有多个进程或服务在使用这个驱动,很难确定是谁的问题,只能排除法。另外,删除驱动后,需要重启验证,如果泄漏缓慢,可能要等待几天甚至几周才能确定问题是否解决。
最近一段时间,Huggingface做了一点改动。
在Space页面,按Space功能加了一行Icon。因为搜索很烂,所以官方归类一下还是不错的。从靠前的Space可以看到比较不错的项目和模型,或者说就是现阶段最好的模型。我试了下靠前的Background Removal项目,就挺好用。
Huggingface大概在一个月前,接入了其他模型供应商。官方自己的接口一直都很烂,不但容易掉线,非热门模型撤得也快,基本只能当玩具。接入第三方后,自然稳定很多。
但是,配额暴降。之前是FREE账户限制模型范围,PRO账户有20K/M的调用次数。现在缩水到FREE账户$0.1/M,RPO账户$2/M。
我测试了一下,在模型页面右侧的使用Demo也会扣配额。Huggingface没有说具体的计算方式,如果是按调用次数,等于PRO用户砍了九成配额。
当然了,也有办法增加配额,我只能说懂的都懂。
更正:Huggingface是按各个服务商的定价按原价转发。
具体的供应商列表在源码的PROVIDER_T里,相应的接口(LLM):`
https://router.huggingface.co/{:PROVIDER}/v1/chat/completions。
有意思的是,如果是走第三方供应商,一些Huggingface上不存在的模型也是可以调用的。但不是所有接口都可以,Huggingface对每个供应商只实现了部分接口,具体可以看源码中的定义。
Space原本是不支持/v1路径的,访问会404,所以作为LLM接口调用必须要多加一层路径(如/hf/v1),现在似乎修好了。
有一段时间没推荐过新模型了,这次推荐的主要是长上下文模型,比较适合角色扮演(当然大部分也是通用模型)。
之前模型百花齐放,主要得益于Yi-34B和Qwen-32B的各种微调。现在这些内容有些过时了,所以这期主要是推荐一些云端模型。
这些模型要么没有审核,要么很容易jailbreak,具体就自己发挥吧。
海螺AI的开源模型,角色扮演型模型。他们家主要就是做角色扮演的,旗下有个叫星野的APP,用的是一个小号模型。
和Deepseek一样,对个人来说开源了等于没开源,体积太大了。
官方的Demo:点这里,我适配的接口:点这里
要稳定的话自己官网注册账号,1M上下文,输入0.001元/千token, 输出0.008元/千token。
这个模型发布后登上了几天Huggingface热门榜,然后就没什么波澜了。官方模型介绍提到「其中每8层中有7个是基于Lightning Attention的线性注意力,有一层是传统的SoftMax注意力」,是不是有点像RWKV?
效果上看:适合角色扮演,但也只适合角色扮演。不要用在需要严谨推理的地方,尤其是不要问数学题。
豆包专门用于角色扮演的模型,这是一个系列,有Lite和Pro以及最多32K上下文的版本,官方每个版本送500万tokens。
我只是浅浅试了一下jailbreak,几乎没有限制,更多的就没有深入体验。
character版本的低限制应该是有意设计的,普通的Pro版本很难越狱(Lite可以jailbreak,但文本质量差很多)。
Gemini 2.0 Flash正式版发布了,可能是受股价下跌的刺激,这次来得很突然。正式版模型有1M上下文,限制比任何实验版都要少。这个模型很强,除了扮演也可以干正事。
在最近的审查选项里,除了BLOCK_NONE外还额外新增了一个OFF。在谷歌给的演示中,HARM_CATEGORY_SEXUALLY_EXPLICIT就是OFF,好像是在暗示什么。我不知道两者有什么区别,总之调成OFF后,正式版几乎不会中断输出。
关于Gemini还有两个小新闻。
第一是,实时搜索功能上线了,好像是仅限付费版,要在tool参数里设置。
第二是,API上的思维链被砍了,只能AI Studio里看到思考内容。我不知道谷歌为什么要这么做,而且就在Deepseek R1刚发布后,感觉纯纯有病。
也是在Deepseek发布后紧急上线的模型,能力比Deepseek强。通用能力强,扮演也强,和Gemini一样,可以作为主力,然后就是贵。刚发布时完全被R1的光芒掩盖了,春节后才开始登上榜单。
官方的Demo:点这里,我适配的接口:点这里
要稳定用的话去官网注册吧,应该是送不少tokens,我估计过阵子价格还会降。
我测试是可以扮演的,但是因为热度的关系,实在是太卡了,也就没深入测试。R1不适合扮演,莫要强求。
自从Yi-34B发布后,我就有个想法,以后只会有小模型和超大模型开源。
原因是小模型是端侧的玩具,几乎不能拿去卖钱;超大模型用来秀肌肉,开了等于没开,如开;中等体量是真的能用,只会便宜了用户和友商。
不过之后一段时间,Qwen仍在继续更新30-40B的模型,我觉得他们或许也是没什么KPI压力。
随着Deepseek R1的发布,我已经遇到了好几个人和我有同样的想法。在受到商业上的刺激后,不知道阿里还有没有心情做这种「慈善型」的中等体量模型。
我在之前的文章里说R1蒸馏进Llama 70B后继承了Llama重复的问题,不过话又说回来,后来我又发现R1蒸馏进Qwen-32B后,继承了审查宽松的特性。
目前R1-Qwen-32B可以通过我的这个接口配合自己的HF Token + Model:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B体验。根据HuggingFace的惯例,一旦热度下降就会撤掉部署,估计随时失效吧。
R1-Llama-70B目前可以在Sambanova体验。不过呢,他们很快就要取消免费版了,所以也是随时失效。或者用我的CerebrasUnofficial也行。
蒸馏版纯属娱乐,不推荐自己部署。
蒸馏版接口 => CerebrasUnofficial
最近Deepseek R1很火,出圈首先是因其成本论述引发英伟达股价下跌而受到关注,之后以其独特的攻击性,再次带动了传播。
我实际体验了一下,说实话,感到一般。
我关注的几个问题:
一、关于CoT(思维链)
我测试下来,效果和Gemini比,差了很多。Deepseek不像是think,而是在understand。
关于CoT我最先接触的是gemini-2.0-flash-thinking,觉得很有意思。当时我在解决一个网络问题,模型的thinking让我看到了它的回溯过程。
类似这样:「用户遇到了XX问题,XX结果说明XX没有问题,再看XX可以排除是XX问题。这也许是XX问题,但是从XX的结果看,问题应该也不在这里。这个问题很奇怪,最好再确认一下……(找不到问题,绕回来要求用户检查)」
虽然最终问题没有解决,不过整个CoT很有逻辑,我也学到了一些东西。
Deepseek给我的感觉不是这样,它更倾向于对输入进行复述。比如说,它会对我的要求分类汇总,然后写出需要遵从、注意的点,整体就是像是润色和扩写prompt,体现不出逻辑推理本身。(顺带一提,它有时还会不按think的内容回应,就好像无视了think过程。)
举个具体的例子,例子中的真实对话大约有17K tokens,这是一个比较长的上下文。内容关于一个盗贼角色,该角色被设定为喜欢“黑吃黑”,经常在交易时击晕交易对象,这次他要交易的是情报线索。「击晕」在这里实际上是陷阱,由于情报的特殊性,对方被击晕就无法说出情报了。
Deepseek在长上下文中表现出一定的混乱,从think阶段就经常搞混身份(很多模型都有这个毛病)。逻辑上,Deepseek也常常意识不到陷阱(中间重试多次),击晕对方后直接退场的几率很高。相比之下,Gemini几乎可以稳定发挥,在think阶段就能意识到需要先套取情报,再进行击晕,或者直接放弃击晕。
Grok、Qwen几乎不会出错,不过没有think过程,所以无法进一步判断。
二、关于成本
有兴趣的可以先了解一下友商零一万物 的文章,Deepseek用到的大部分的方法其中都有提到,包括MoE的优化,整体算是科普向。
Deepseek首次在超大模型中使用了混合精度,重点是给出了哪里可以省精度,哪里又不能省。这个属于「我的成功可以复制」,是很重要的贡献。
还有一些是不能复制的,比如说Deepseek训练框架,通过很底层的魔改,实现了更高的并行效率。这种魔改已经接近汇编了,独此一家。
题外话,有传言说Deepseek绕过了CUDA直接驱动显卡,这种能力可以立刻迁移到其他硬件,从而打破英伟达的垄断。这个说法是错误的,具体就不展开了。
这次成本很大一块是通过「CoT可以靠GRPO+RL涌现」来缩减。简单点说,就是不需要标注,直接告诉模型答案,但只能解决已知答案的问题,例如 数学问题,而RL达成了泛化(事实上对于没有答案的问题,还是加入了一定的SFT(监督微调))。我对此表示怀疑,目前Huggingface的团队正在尝试复现,可以继续关注。
Deepseek R1的创作能力排行已经超越Claude,表现在它很有趣、很会阴阳,这和语料是分不开的。实际上R1最后还是经过了两轮SFT,这个成本不仅省不了,而且对语料要求还很高。为了突显CoT部分省成本,这个成本被隐藏了。
还有一些推理方面的成本,不算很重点,略去。
三、蒸馏的效果
这里我使用的是Cerebras提供的deepseek-r1-distrill-llama-70B版本。
作为测试,我做了一个非官方接口。具体的部署方式,查看项目主页即可,此处不展开。
我对蒸馏效果的印象是:形似,但继承了各自的问题。
测试文本大约有15K tokens,此时模型大部分时候还保持think(有时会输出<think></think>省略思考),但很大概率会重复用户的话。这种重复几乎就是逐字逐句,整片大段的重复(这是很多模型在长上下文场景中的通病)。
总结就是,蒸馏版既有Deepseek think等于没think的问题,又有Llama 70B重复的毛病。当然,意义是把CoT迁移到小模型,对需要本地部署的人来说比较重要。
四、商业影响
Deepseek最重要影响是引发行业对成本的关注。从投资角度看,Deepseek冲击的是FOMO情绪,利好除了英伟达以外的所有巨头。
为什么说只利好巨头呢?因为从技术角度看,很难带来大规模的成本下降,也谈不上威胁英伟达的地位。要想实现人人有丹炼,短时间内还不太可能。
五、其他
自动Deepseek火了以后,本地部署Deepseek的文章、视频突然冒出来,这类内容大部分介绍的是完整版R1,实际部署的是蒸馏版,有些甚至是7B以下的超小版本。要知道,一个完整版的R1,在Q4精度下,大约需要400G的内存/显存。这种宣传和诈骗有什么区别?如果真的需要迷你模型,这个尺寸有非常多的选择。
我的建议是,个人用户不要尝试自己部署任何版本,真想用就用官方API。或者,用英伟达的NIM接口,每号1000次对话,可以无限注册。
服务器因为用过warp脚本后定期失联的问题已经困扰我很久了。
用尽各种方式,以及各种缓解手段,服务器最后还是失联,甚至都找不到任何可疑的进程或服务。试了下debian,也是没辙。
俗话说天下无难事,只要肯放弃。
新开一个服务器,再也不碰warp了,以后就用redsocks+分流的方案。