我习惯使用Windows睡眠,很少关机。但是系统总是越用越卡,最终不得不重启。这个情况持续了很长一段时间,64G的内存基本上只能支撑1-2周,并且一直找不到原因。
最近,这个问题终于彻底解决。流程和和这篇《win10非分页缓冲池占用过大的解决方法》几乎一致。
内存泄漏的情况千奇百怪,总有前人踩过坑。然而,往往要已经定位到问题,才能搜到对应的文章,属于是马后炮了。所以我姑且记录一下自己的流程。
首先,查了一些常见的系统泄漏情况,关闭了微软输入法,无效。
接着,用Process Explorer查找问题,没有异常进程。
继续研究,有一些用户提到显卡驱动有内存泄漏,如果是这种驱动级泄漏,Process Explorer是找不到的。
ChatGPT的解释:
Process Explorer 本身主要用于查看和分析用户模式下的进程和线程活动,比如 CPU、内存、句柄和 DLL 的使用情况。
它不直接提供定位驱动级别内存泄漏的功能,因为驱动程序运行在内核模式下,而 Process Explorer 主要关注用户模式的行为。
系统开机一段时间后,用PoolMonX查驱动,Diff排序,此时FMfn攀升到第一位。
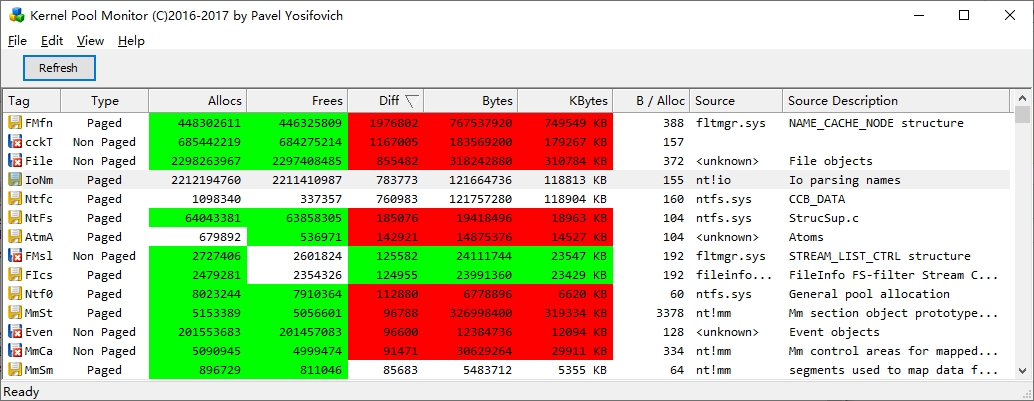
按照网上的说法,应该要查Non Paged,不过我这里显示是Paged。Diff代表申请和释放内存的差值,如果数字太大,代表没释放的内存在堆积。
C:\WINDOWS\system32>fltmc
筛选器名称 数字实例 高度 框架
------------------------------ ------------- ------------ -----
cbfs6 <过时>
bindflt 1 409800 0
lrtp 17 389170 0
sysdiag 7 324600 0
storqosflt 0 244000 0
wcifs 1 189900 0
CldFlt 10 180451 0
FileCrypt 1 141100 0
luafv 1 135000 0
npsvctrig 1 46000 0
Wof 13 40700 0
FileInfo 17 40500 0
问一下ChatGPT这都是些什么:
cbfs6:通常与 Callback File System 相关,这是一个用于开发虚拟文件系统的第三方工具。
bindflt:Windows 内置驱动,绑定筛选器驱动程序,用于文件系统绑定操作。
lrtp:未知,这个名称不像常见的系统驱动,可能需要更深入的检查。
sysdiag:未知,名称看似与系统诊断有关,但没有明确的 Windows 系统驱动使用这个名称。
storqosflt:Windows 内置驱动,存储质量服务过滤器,与存储设备的性能管理相关。
wcifs:Windows 内置驱动,Windows 容器隔离文件系统,支持容器化文件操作。
CldFlt:Windows 内置驱动,Cloud Files Mini Filter Driver,用于 OneDrive 等云存储服务的文件占位符功能。
FileCrypt:Windows 内置驱动,文件加密驱动,处理文件级别的加密操作。
luafv:Windows 内置驱动,用户账户控制虚拟化,用于兼容旧软件的 UAC 虚拟化支持。
npsvctrig:Windows 内置驱动,服务触发器提供程序,用于触发基于网络事件的服务操作。
Wof:Windows 内置驱动,Windows Overlay Filter,用于处理压缩和解压缩的文件存取操作(如 NTFS 压缩或 WIM 挂载)。
FileInfo:Windows 内置驱动,文件信息筛选器,用于收集文件元数据,常用于安全审计。
有两个未知,其中sysdiag是火绒。继续定位lrtp.sys:
C:\>findstr /m /l /s lrtp *.sys
Program Files (x86)\Lenovo\LenovoInternetSoftwareFramework\lrtp.sys
FINDSTR: 无法打开 swapfile.sys
Windows\System32\drivers\lrtp.sys
原来是联想的东西,搜了一下,这个驱动属于老版本的管家残留,新版本已经换驱动了,所以无法通过装新版再卸载来解决。网上大概有三四篇文章提到这个驱动存在内存泄漏,包括开头提到的那篇。
总之,可以暴力删除,也可以用这篇文章末尾的批处理:《联想电脑管家卸载残留完整分析》
至此,系统内存泄漏问题解决。
题外话,通过这次排查,我才知道任务管理器的使用中内存根本就是文字游戏,备用内存更是毫无意义的数字。
使用中代表这部分物理内存正在使用,但真正不能释放的部分是已提交。打个比方,有人预订了酒店,但他不一定入住,酒店没办法把这些空房安排给其他客人。预订就是已提交,使用中就是实际入住,有人占着茅坑不拉屎,不等于茅坑能再次分配。
备用就更没有意义,这个数字等于物理内存总量减去使用中。其中既有不能释放的申请,又包括了可以释放的缓存。这个名称给人一种”这些内存在必要时可以分配给其他应用“的错觉,我不知道计算这个的意义是什么。
内存释放工具主要就是转移这部分内存,这些数据被暂时移到硬盘后,又会被系统慢慢加载回来,所以解决不了内存爆炸后的卡顿的问题,最多只能缓解几分钟。而频繁清理,硬盘压力会变大,只会使系统更加卡顿。
一个典型的例子是Photoshop。在Photoshop中关闭文件后,这部分内存并不会被释放。官方的解释是,软件为了不反复申请内存,所以不释放内存,而是留着给未来的操作重用。实际上,这就是典型的内存泄漏,而且这些内存根本不像官方说的那样会重用。
如果用内存清理软件清理,这些物理内存占用快速下降,但是观察进程管理器,可以看到内存很快又会攀升,并且磁盘忙碌。整个过程最多5分钟,已提交的数字不会变化,等于是这些内存去分页文件逛了一圈。这时候,唯一能做的就是重启Photoshop。
驱动级泄漏最麻烦的地方在于,如果有多个进程或服务在使用这个驱动,很难确定是谁的问题,只能排除法。另外,删除驱动后,需要重启验证,如果泄漏缓慢,可能要等待几天甚至几周才能确定问题是否解决。