最近有人提到了百度飞桨的免费GPU算力,所以就看了下。
目前飞桨每天提供8算力点,可以用四个小时16G V100。
和Kaggle相比,两者免费总时长差不多,不过体验有些区别:
- 飞桨默认16G V100 ,Kaggle默认16G T4双卡
- 飞桨可选32G V100,时长相应也只有一半
- 飞桨自带Code Server,可以和Jupyter一起用
- 飞桨没有root权限,不能
apt install
- 飞桨有100G的空间,Kaggle只有20G
- 飞桨的联网很成问题,要先搞定代理
以上除了硬件限制,其他都是可以绕过的。总体而言,由于绘图不能分卡加载的缘故,飞桨适合需要大显存的绘图场景,不过相应的每天只能用2小时。
开始正题,如何使用vscode远程连接?
最简单的答案:使用 handy-ssh 开启一个简单的ssh server,然后使用 netapp 进行穿透。结束。
接下来是一些细节,甚至创建虚拟的root环境,算是对colab、kaggle、huggingface space折腾成果的综合应用。
一些细节
持久化
首先是持久化,/home/aistudio/external-libraries 是永久保存的。任何环境配置都应该在这个目录下进行。
使用code server,新建终端,可以同时运行多个命令。
必要的代理
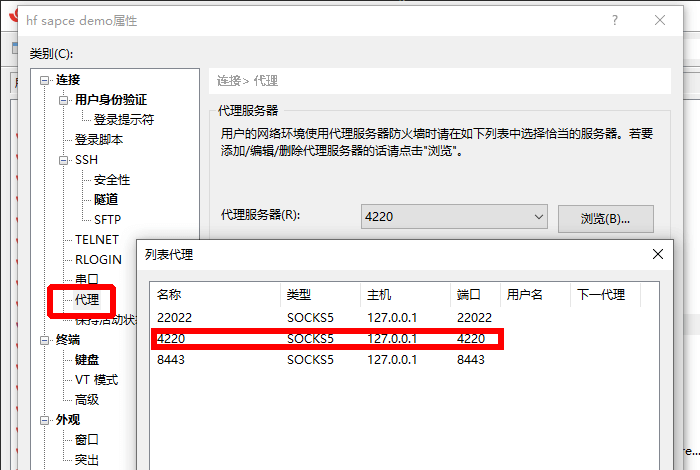
强烈建议先配一个梯子 + proxychains 强制代理。
尽管本文未用到proxychains,但还是建议配一个,这会减少很多麻烦(例如 直接从github拖东西,而不需要找镜像、手动上传,或是翻阅各个软件的代理配置)。
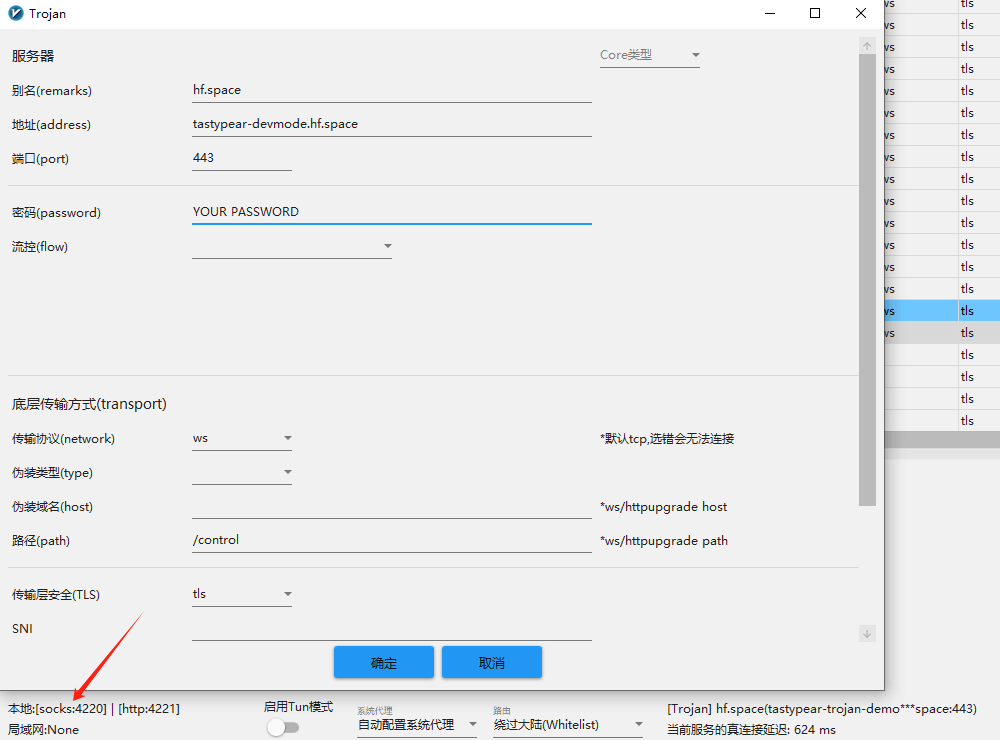
我的方案是 glider 连接 vless,二进制文件直接通过code server传上去即可。
# 在9050开启socks5和http代理,服务器必须是443端口的
./glider -listen :9050 -forward wss://HOST/PATH,vless://UUID@
# 自行编译proxychains,bin+.so+config
./proxychains4 -f config.conf YOUR_COMMAND
# 配置见/src/proxychains.conf,最后socks4改为socks5
建立ssh server
接着把 handy-ssh 传上去,开启一个22122端口的ssh server,用户名为aistudio,密码为root
./handy-sshd --user aistudio:root -p 22122
自建穿透服务
选择netapp穿透的原因是,飞桨对端口卡得恨死,而netapp的服务正好在443端口。由于注册netapp需要身份证,嫌弃的话也可以自己搭一个。
我用的是 wstunnel
# 服务端
./wstunnel server ws://127.0.0.1:PORT -r PASSWORD
我是用nginx将PORT反代,同时加上证书和域名,这样就得到了一个443端口的穿透专用服务。
./wstunnel client -R tcp://0.0.0.0:22122:localhost:22122 wss://HOST -P PASSWORD
在飞桨里连接服务器,这样就完成了ssh server的部署。
最后通过vscode连接到aistudio:root@HOST:22122。
不需要root环境的话到此为止。
ROOT和开发环境的持久化
使用miniconda将udocker部署到持久化目录,再通过udocker获得一个root权限的容器,以运行简单的apt install。
安装miniconda
# 安装miniconda3并创建独立环境my_env
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash miniconda.sh
source /home/aistudio/miniconda3/bin/activate
conda create --name my_env
conda activate my_env
conda init --all
安装udocker
重新开启一个终端,使用which python确保使用刚安装的miniconda3,接着安装udocker。
# ~/.udocker是无法持久化的,所以创建一个软链接
ln -s ~/external-libraries/.udocker ~/.udocker
python -m pip install udocker
如果配置了代理,通过代理使用udocker install完成安装。没有代理的话,上传udocker-englib.tar.gz,然后通过 export UDOCKER_TARBALL=udocker-englib.tar.gz指定,实现脱机udocker install。
配置udocker环境
如果是GPU环境,可以通过udocker setup --nvidia ubuntu将宿主GPU配置复制到容器内。之前在colab上绘图时试过可用,记得是不需要什么额外设置,飞桨没试。
# 选择focal版本(同宿主),假设配置了代理:
udocker pull --httpproxy=socks5h://127.0.0.1:9050 ubuntu:focal
udocker create --name=ubuntu ubuntu:focal
udocker run --entrypoint=sh ubuntu -c "echo root:root | chpasswd"
# 这步是安装scp,有error无视,也可以从宿主环境复制
udocker run --entrypoint=sh ubuntu -c "apt update"
udocker run --entrypoint=sh ubuntu -c "apt install openssh-client"
# 挂载目录并运行ssh server
udocker run -v /home/aistudio/miniconda3 -v /home/aistudio/external-libraries:/root -p 22122:2222 --entrypoint=sh ubuntu -c "~/handy-sshd --user root:root"
运行时,我将miniconda3直接挂载到容器内,这样容器就不用再安装一遍。同时,我将持久化目录直接当作容器的主目录,这样之前准备的handy-ssh、glider、wstunnel在容器内就可以直接用。
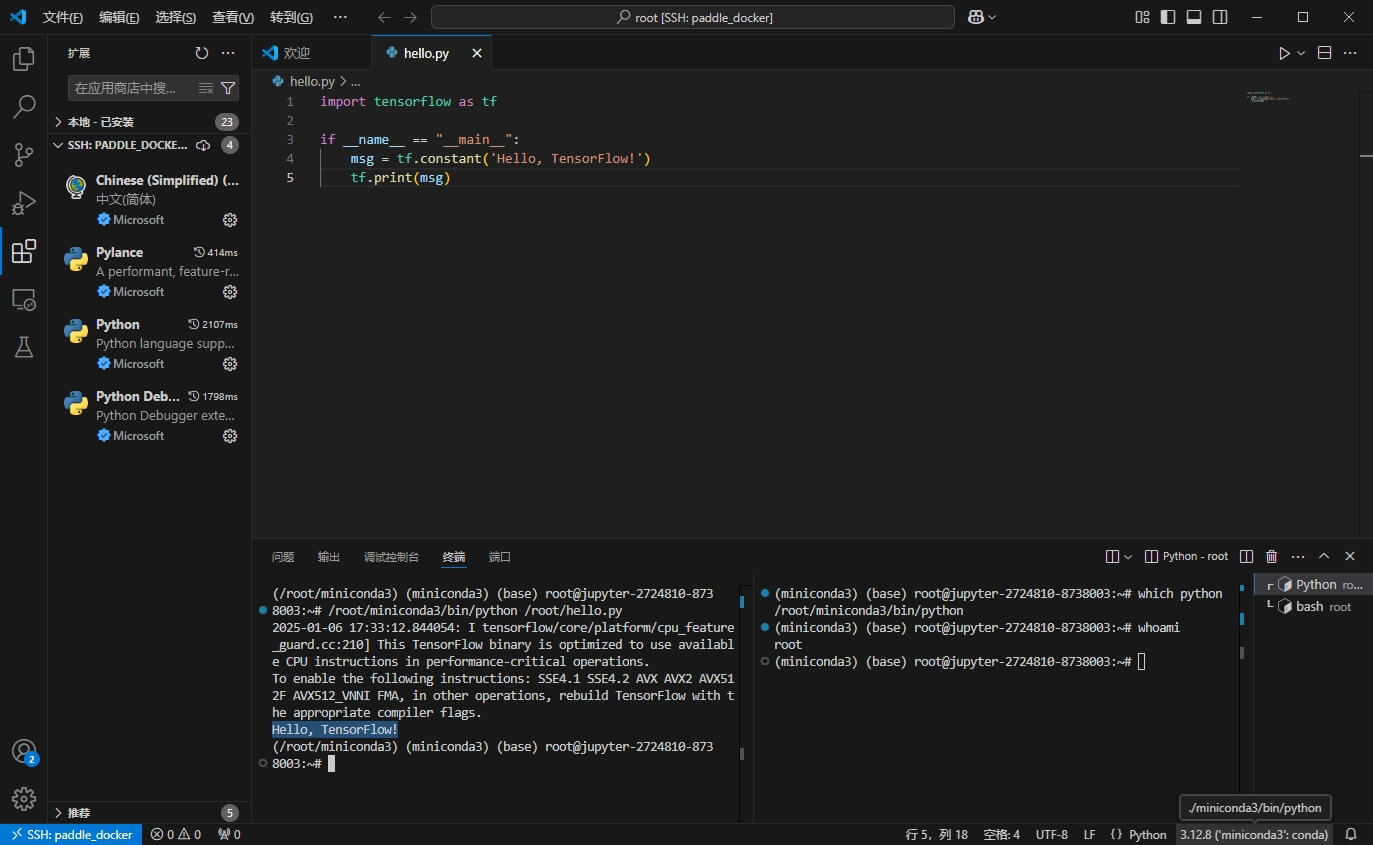
宿主机穿透后,vscode就可以通过ssh连接root:root@HOST:22122,访问udocker内的环境。
此时vscode无法自动找到python,需要在vscode的终端中ln -s /home/aistudio/miniconda3 ~/miniconda3,然后重启vscode,就可以自动发现解释器了。
要注意的是,不能使用 -v /home/aistudio/miniconda3:/root/miniconda3挂载,因为miniconda3在安装后的配置里写死了路径,导致容器内也只认/home/aistudio/miniconda3,这会导致vscode调用时出现混乱。
重启后的环境重建
重启后,非持久化的内容就丢失了,恢复环境需要这些步骤:
# 重新激活 miniconda
source /home/aistudio/miniconda3/bin/activate
conda activate my_env
conda init --all
# 创建软链接
ln -s ~/external-libraries/.udocker ~/.udocker
# 重新建立穿透
cd /home/aistudio/external-libraries
./wstunnel client -R tcp://0.0.0.0:22122:localhost:22122 wss://HOST -P PASSWORD
# 终端新建分屏,开启ssh server
# 无udocker宿主环境
/home/aistudio/external-libraries/handy-sshd --user aistudio:root
# 有udocker的虚拟ROOT环境:
udocker run -v /home/aistudio/miniconda3 -v /home/aistudio/external-libraries:/root -p 22122:2222 --entrypoint=sh ubuntu -c "~/handy-sshd --user root:root"