写于2024年1月。请注意内容是否过时。
之前写了一篇《一些中文LLM的试用体验》,内容有点过时。结合目前的情况更新一下。
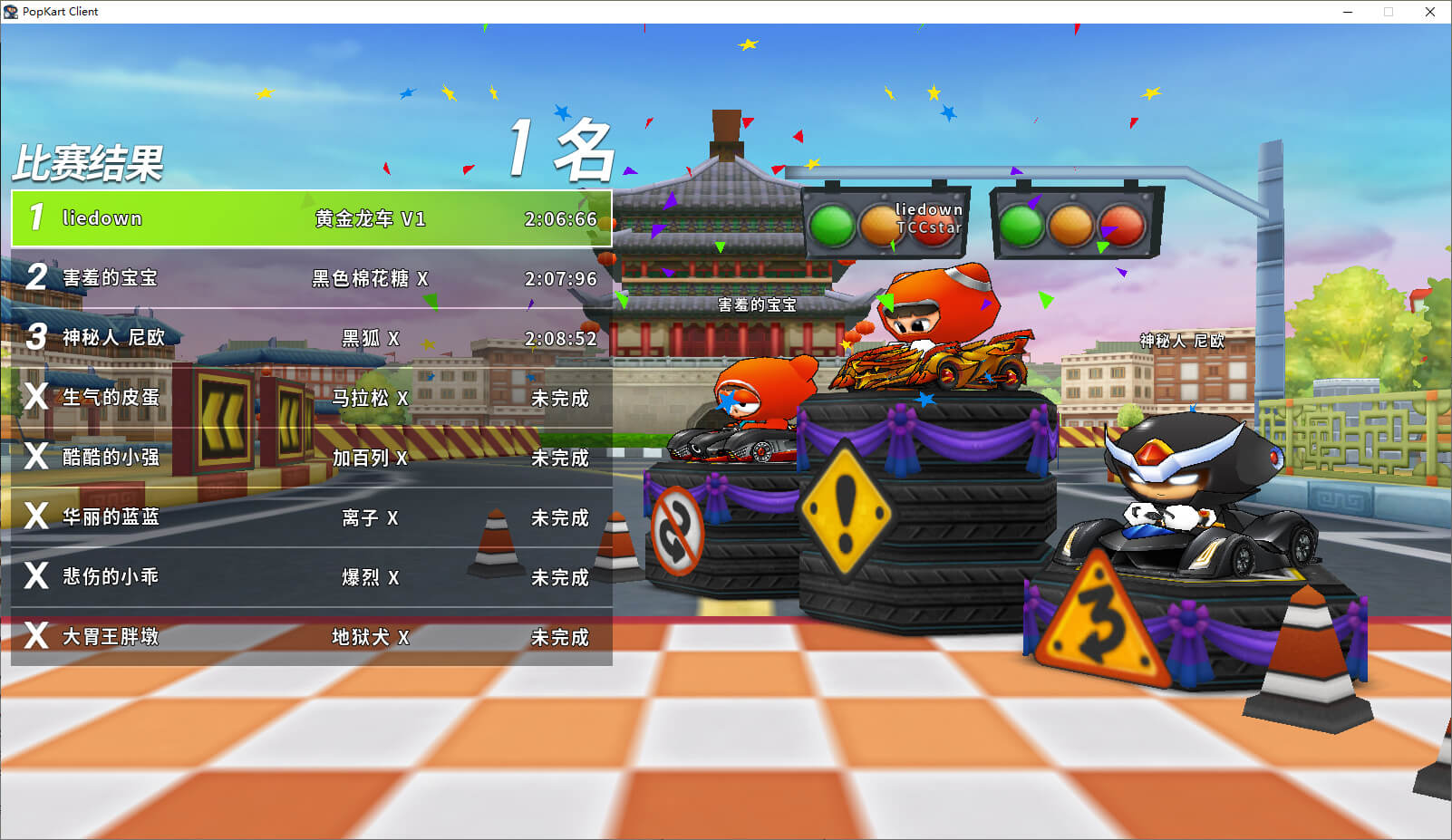
依然以家用环境或免费的网络服务为主,也就是说不会出现超过 40B 的模型。
这里要特别提一下 MoE 模型,以 Mixtral-8x7B 为例,这个模型一次只调用 14B,但加载消耗的硬件与 ~40B 的模型相当。MoE 对个人自用来说是不划算的,只适合作为服务部署。
目前好用的中文模型:
这里尤其特指中文模型,因为中文模型比较少,更有不少是浪得虚名。中英文混杂输出是常见病,有些连句子都输出不通顺,这种东西只能自己试了才知道。
NSFW 篇:
非 NSFW 篇
不确定的小模型
※ 部分模型一直在更新版本,具体可以在使用前翻阅作者的模型列表。
当前自用部署量化的情况:
大部分人用的是 text-generation-webui,但我很少用“懒人包”,因为我需要在服务器部署,然后通过兼容 OpenAI API 的接口给本地使用。
目前主流的量化格式包括 GGUF(llama.cpp)、GPTQ、AWQ、exl2(ExllamaV2)。RWKV 另说。
具体推理速度和硬件需求参考这篇 对比文章。
总结:exl2 作为 GPTQ 的改良版非常快,GPTQ 和 AWQ 很接近,但 GPTQ 在处理 prompt 阶段明显更快,这对于超长文本比较重要,GGUF 是最慢的。
所以我推荐的是 GGUF。是的,GGUF 是最慢的,但是推荐。
先说 GGUF。家用硬件性能有限,使用模型都是奔着榨干性能上限去,而量化需要更多的资源,大量现成的 GGUF 就很实用。GGUF 还可以混合 CPU 和 GPU 部署,实在没显卡的话,慢总比不能用好。
GGUF 虽然慢,但也没有非常慢,相对 GPTQ 和 AWQ 并没有量级差。只要输出速度没有拖累阅读速度,就不会感觉到卡顿。
最最最重要的是独立二进制文件,不会存在依赖问题。
GGUF 如果部署为 server,有两种方案。
第一种最简单,用 llama.cpp-python,并且有现成的 cuBLAS wheel。
# 以colab环境为例
!pip install llama-cpp-python[server] --prefer-binary --extra-index-url=https://jllllll.github.io/llama-cpp-python-cuBLAS-wheels/AVX2/cu118
!python -m llama_cpp.server --model ./model.gguf --n_gpu_layers 1000 --chat_format chatml --host 0.0.0.0 --port 8000
不过这里有个问题,chat_format 是写死在代码里的,要改需要改源代码,自己重新编译。如果模板里正好有对应的格式,那这个最方便。
第二种是直接从 llama.cpp 编译 server。这里我以 Kaggle 环境为例,因为它的 libcuda.so 位置比较刁钻,需要修改一下源码才能编译。
%cd /kaggle
!git clone https://github.com/ggerganov/llama.cpp
%cd /kaggle/llama.cpp
!sed -i 's| -lcuda | -L/usr/local/nvidia/lib64 -lcuda |g' /kaggle/llama.cpp/Makefile
!make -j server LLAMA_CUBLAS=1
编译完成后的二进制文件可以保存下来,下次就可以直接拿来用了。
server 提供的接口不是 OpenAI 格式的,可以启动项目中的 api_like_OAI.py 兼容。这里可以参考 llama-cpp-oai-like-server。我做了一个不太优雅的兼容,重点是很容易定义聊天格式,直接替代原始的 api_like_OAI.py 使用。
然后说 GPTQ 和 AWQ。比较常见的是用 auto-gptq 和 auto-awq 加载。但是这两个模块经常会受到上游包更新的影响,例如 transformer。一旦出现冲突,就需要等作者更新。
如果经常在 Colab 这种环境跑,每次都是新安装,部署就容易出问题。
此外,GPTQ 要求所有模块使用 GPU 版本,不然只能关闭 Exallma,这会很影响推理速度。
如果一定要用的话,推荐 AWQ+fastllm(不要用 vllm,问题实在太多)
Colab 版本大致如下:
!pip install "fschat[model_worker,webui]"
!pip install auto-awq
!python -m fastchat.serve.controller --host 0.0.0.0 &\
python -m fastchat.serve.model_worker --model-path Author/M-AWQ --host 0.0.0.0 &\
python -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 8000
接着说 exl2。很快,但资源很少,量化是最最最耗时的,一个次量化几小时不算长。除非是决定日常要一直用某个模型,或者要部署成在线服务,否则不太推荐。
最后说 RWKV。RWKV 属于比较奇怪的存在,有两种方法在服务器上部署。
第一种是用 cgisky1980/ai00_rwkv_server。比较有意思的是这个项目用的是 webGPU 而不是 CUDA。
Colab 环境的重点是要安装 libnvidia-gl-XXX 这个包。其他跟随项目介绍就行了。
并不太推荐。一是不能多卡部署,二是报错不太友好有问题难定位,三是 KV Cache 有点问题。
第二种是用 josStorer/RWKV-Runner。要分两步执行,大致如下:
# 启动一个后端
import os
os.environ['RWKV_CUDA_ON'] = '1'
!python ./RWKV-Runner/backend-python/main.py --port 8000
# 通过 API 加载模型
curl http://your.site/switch-model -X POST -H "Content-Type: application/json"\
-d '{"model":"./RWKV-Runner/models/the_model.pth","strategy":"cuda:0 fp16 *20 -> cuda:1 fp16"}'
加载策略(strategy)参考 这个指南。怎么量化就只能怎么加载,想要改只能重新量化。
支持多卡,但多卡推理时会遇到一点问题,输出结果有折扣,暂不清楚原因。
结论就是:RWKV 在多卡方面都会遇到挫折。
总结:
当前非常推荐 GGUF,尽管相比其他量化慢一些,但最不容易随升级出问题。而且在线临时环境部署非常轻松,可以直接使用以前生成的 binary,而不需要每次都安装很多依赖。
未来可能会推荐 exl2,视其生态发展而定。