Huggingface 给每个人无限量的临时 Space 配额,试了试居然可以运行代理:一个简单的 Trojan 示例。
直接 Dumplicate,然后修改 PASSWORD 和 WS_PATH 两个 secret 就能启动了。
WS_PATH(伪装路径)不是必须的,删掉它就等同于跑在首页上。
HF Space 踩坑记录
① websocket 问题
代理协议要套用 websocket 才能连接成功。由于很多聊天 Demo 的流式输出都基于 websocket,倒是不用担心像 Colab 那样被掐。
② binding host 问题
始终使用 0.0.0.0 而非 127.0.0.1,否则可能会出现奇奇怪怪的状况。Space 必须要 Public,否则知道 hf.space 地址也不能连接成功。
③ 卡 Starting 问题
即使 Space 内的程序已经正常 Running,仍有可能卡在 Starting。
如果一切正常,且有服务占用 7860 端口(默认端口),Space 状态理应切换为 Running。但 HF 对端口占用检测有 Bug,此时 Space 就会无限 Starting。由于只有 Running 状态,端口才会转发数据,所以此时即使服务正常也无法访问。
解决办法:在启动脚本里加上一句 python -m http.server 7860 & kill $! 。也就是用一个 HF 能识别的服务进程占用 7860 端口后立刻杀掉,再在这个端口上运行其他服务。
④ 保活问题
每个 Space 的运行时间是 48h,之后”不活跃“的 Space 将进入睡眠。之前我猜测只要 .hf.space 有访问就能保活,后来看到确实有人引入 upapp 来检测自己保活。这样的话应该也可以用 UptimeRobot 这类第三方检测来定期访问保活。
⑤ 滥用问题
HF 好像没有具体说明代理是否属于滥用,不过大规模滥用应该是不可能的,只适合自用或备用。第一,HF 给每个用户(对,是账户下所有 Space)分配了 3 个 固定 IP,没有 AnyCast,所以不太可能被批量白嫖。第二,所有 IP 都在美国,延迟一般,也无法绑定域名。
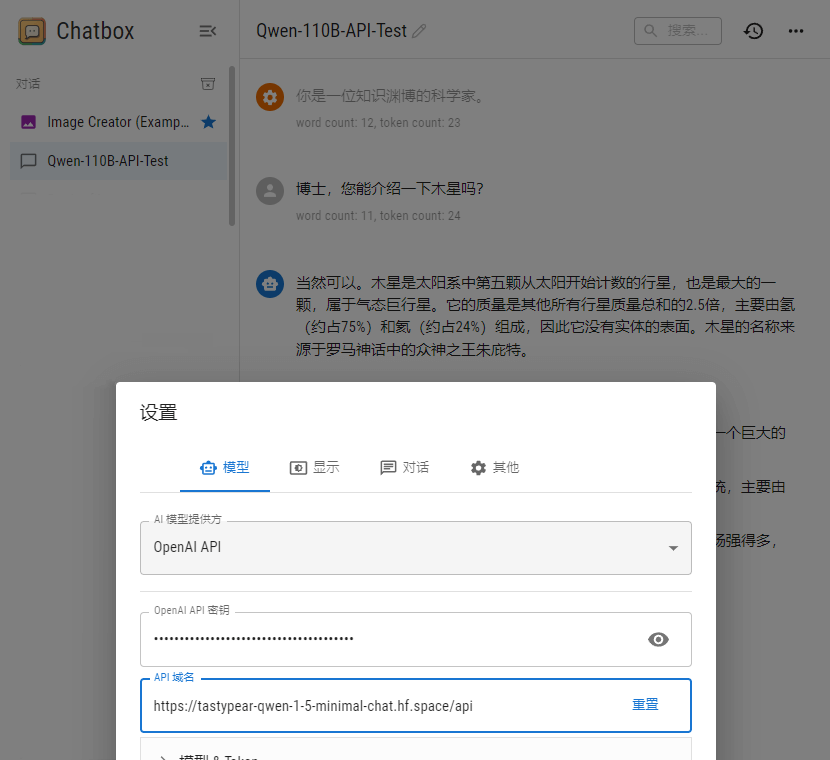
之前提到,Qwen 官方提供了一个在线 Demo。本来是基于 Gradio 的,我将它转换成了 OpenAI 的接口,并且直接部署在了 HF 上: Qwen 1.5 minimal Chat
虽然名字叫 minimal,实际接入的是 110B…… 本地连 7B 都费劲,只能白嫖官方勉强维持生活。
碎碎念:HF space 的 Docker 还是有点奇怪的,调试完了新建项目再部署,就出现 .sh 文件找不到。折腾了半天用 bash 就可以,直接 ./ 就不行,莫名其妙。
因为 HF space 有 48h 不访问就 sleep 的限制,我加上了一个每隔一小时访问自己的脚本,看看能不能绕过这个限制。
Qwen1.5-110B 发布,官方提供了一个在线版,可以通过代码简单调用,以下是一个简单示例。
测试了一下,Jailbreak 比较简单,但一股 GPT 味,不太好玩。理解偏强吧,但做推理题还是不行。
import requests
import random
import string
base_url = 'https://qwen-qwen1-5-110b-chat-demo.hf.space'
# gen random char(11) hash
chars = string.ascii_lowercase + string.digits
session_hash = ''.join(random.choice(chars) for _ in range(11))
json_prompt = {
'data': [
'What is your name?', # prompt
[
## chat history
# [
# 'What is your name?',
# 'I am Alice. How can I assist you today?'
# ],
],
'You are Alice, a human girl.', # system prompt
],
'fn_index': 0,
'session_hash': session_hash,
}
response = requests.post(f'{base_url}/queue/join', json = json_prompt)
response = requests.get(f'{base_url}/queue/data?session_hash={session_hash}')
print(response.text)
最近,关于服务安全,发现一个有趣的结论——把服务建在不常用的端口上会降低而非提升安全性。比如说 MySQL 该建在 3306 就建在 3306,不要去换端口。这个主要是针对集群部署来说。
以曾经的经验,更改服务端口通常可以避免被一般工具扫描。然而,现代的网络空间测绘已经把整个网络扫了个遍。即使更换端口,这些服务仍然已经被识别并被纳入数据库。这些非默认端口的服务,反而成了某种特征。
采用同一批非常规端口的服务器,通常由同一个运维或同一套脚本部署。一旦其中一台机器有漏洞,通过端口,就可以从茫茫 IP 中筛选出所有机器,从而集中爆破。如果这些服务没有修改端口,要找到它们反倒要花更多的功夫。
总的来说,任何响应信息都不该包含具有特征的内容,以免被定位到整个集群。
根据 Colab 的特性更新了脚本,启动时间缩短到 2 分钟左右。
# 核心部分
!wget -q -c 'https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64' -O cfd
!chmod a+x cfd
!pip install --prefer-binary udocker
!udocker --allow-root pull ubuntu:latest
!udocker --allow-root create --name=ubuntu ubuntu:latest
!udocker --allow-root setup --nvidia ubuntu
!pip install --prefer-binary -r https://raw.githubusercontent.com/comfyanonymous/ComfyUI/master/requirements.txt
!pip install --prefer-binary -r https://raw.githubusercontent.com/ltdrdata/ComfyUI-Manager/main/requirements.txt
!udocker --allow-root run -v /usr --entrypoint=sh ubuntu -c "git config --global http.sslVerify false"
!udocker --allow-root run -v /usr --entrypoint=sh ubuntu -c "git clone https://github.com/comfyanonymous/Comfy\UI"
!udocker --allow-root run -v /usr --entrypoint=sh ubuntu -c "cd ComfyUI/custom_nodes; git clone https://github.com/ltdrdata/ComfyUI-Manager"
# 启动部分
!nohup ./cfd tunnel --url http://localhost:88 2>cf.log 1>/dev/null &
while True:
with open('cf.log', 'r') as f:
for l in f:
if ".trycloudflare.com" in l:
print('WebUI URL: ',l[l.find("http"):-2].strip())
break
else:
import time; time.sleep(0.5)
continue
break
!udocker --allow-root run -p 88:8188 --hostenv -v /usr -v /etc --entrypoint=sh ubuntu -c 'cd ~/ComfyUI; python main.py --preview-method auto'
# CPU 运行在 python main.py 启动参数里加上 --cpu
如何做到的?
旧版使用的是 ComfyUI-Manager 里的安装脚本,它默认创建一个隔离的 python 环境,这需要重新安装所有依赖。
由于 Colab 本身已经安装了大部分库,我们可以直接利用起来。Colab 还对 Cuda 相关包做了缓存,所以不指定版本可以省去不少下载时间,同时也节省了空间。现在,udocker 只负责隐匿程序目录,环境均在宿主处理。
此外,还稍微完善了一下 WebUI 入口展示方式,不再需要手动打开文件查看了。
以下是旧的通用脚本
之前写了个 Stable Diffusion 版本的,这次是 ComfyUI 版本。
以下是 CPU 版本,GPU 只要把注释的两行打开即可。
启动大约需要 7 分钟,空框架不含模型。web 入口在 access.txt 中,可以通过侧边管理查看。
!wget -q -c 'https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64' -O cfd
!chmod a+x cfd
!pip install udocker
!udocker --allow-root pull ubuntu:latest
!udocker --allow-root create --name=ubuntu ubuntu:latest
# !udocker --allow-root setup --nvidia ubuntu
!udocker --allow-root run --entrypoint=sh ubuntu -c 'apt update; apt install -y git python-is-python3 python3.10-venv python3-pip wget'
!udocker --allow-root run --entrypoint=sh ubuntu -c 'wget -O - https://raw.githubusercontent.com/ltdrdata/ComfyUI-Manager/main/scripts/install-comfyui-venv-linux.sh | bash'
!udocker --allow-root run --entrypoint=sh ubuntu -c 'pip cache purge'
!nohup ./cfd tunnel --url http://localhost:8433 > access.txt &
# !udocker --allow-root run -p 8433:8188 --entrypoint=sh ubuntu -c './run_gpu.sh'
!udocker --allow-root run -p 8433:8188 --entrypoint=sh ubuntu -c './run_cpu.sh'
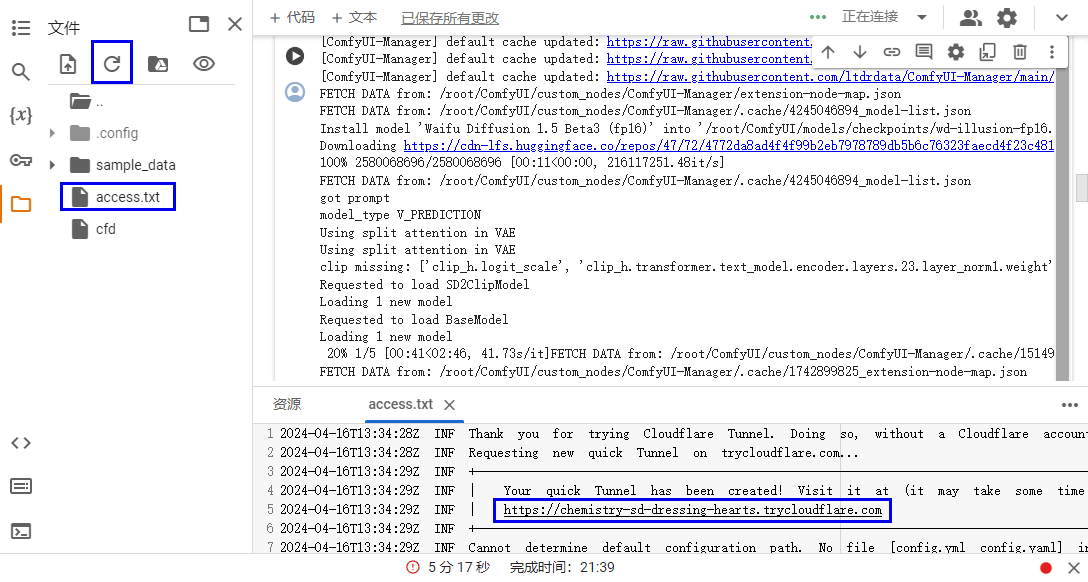
这里面有不少的坑,有一些还莫名其妙,这里稍微记录一下。
- 尽量不用别人现成 docker image,因为结构可能奇奇怪怪。如果深入到容器内修改文件,可能连基本命令都找不到。之前就遇到过用 ChromiumOS 做容器的,wget 难以安装(最后利用 python wget module 替代)。
- Colab 对画画的检测还是挺多的,直接安装必然会被掐。如果通过 apt 安装 cloudflared 并通过 thread 调用也会被掐,不知道是哪个环节影响的。
- cloudflared 使用自定义域名会导致 ComfyUI-Manager 有几个 js 502 错误无法加载,使用快速随机域名 tunnel 就不会。查了下可能和 tls verify 设置有关,但现在 Cloudflare 后台砍掉了这个设置,暂时不知道去哪改。
众所周知,colab 已经屏蔽了 stable diffusion,既有文本的粗暴过滤,也有运行时特征检测。就算没有限制,要跑通也不是很轻松的事,而且随时可能因为版本依赖问题歇菜。
这里演示一种简便的绕过方法——使用 docker。
直接上代码,其实都不到 10 行:
!wget -q -c https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64 -O /tmp/c
!chmod a+x /tmp/c
!pip install udocker
!udocker --allow-root pull universonic/stable-dif${q}fusion-webui:latest
!udocker --allow-root create --name=sdw universonic/stable-dif${q}fusion-webui:latest
!udocker --allow-root setup --nvidia sdw
!udocker --allow-root run --entrypoint=sh sdw -c 'pip cache purge'
!/tmp/c tunnel --url http://localhost:88 &\
udocker --allow-root run -p 88:7860 --entrypoint=sh sdw -c '~/stable-dif${q}fusion-webui/webui.sh -f'
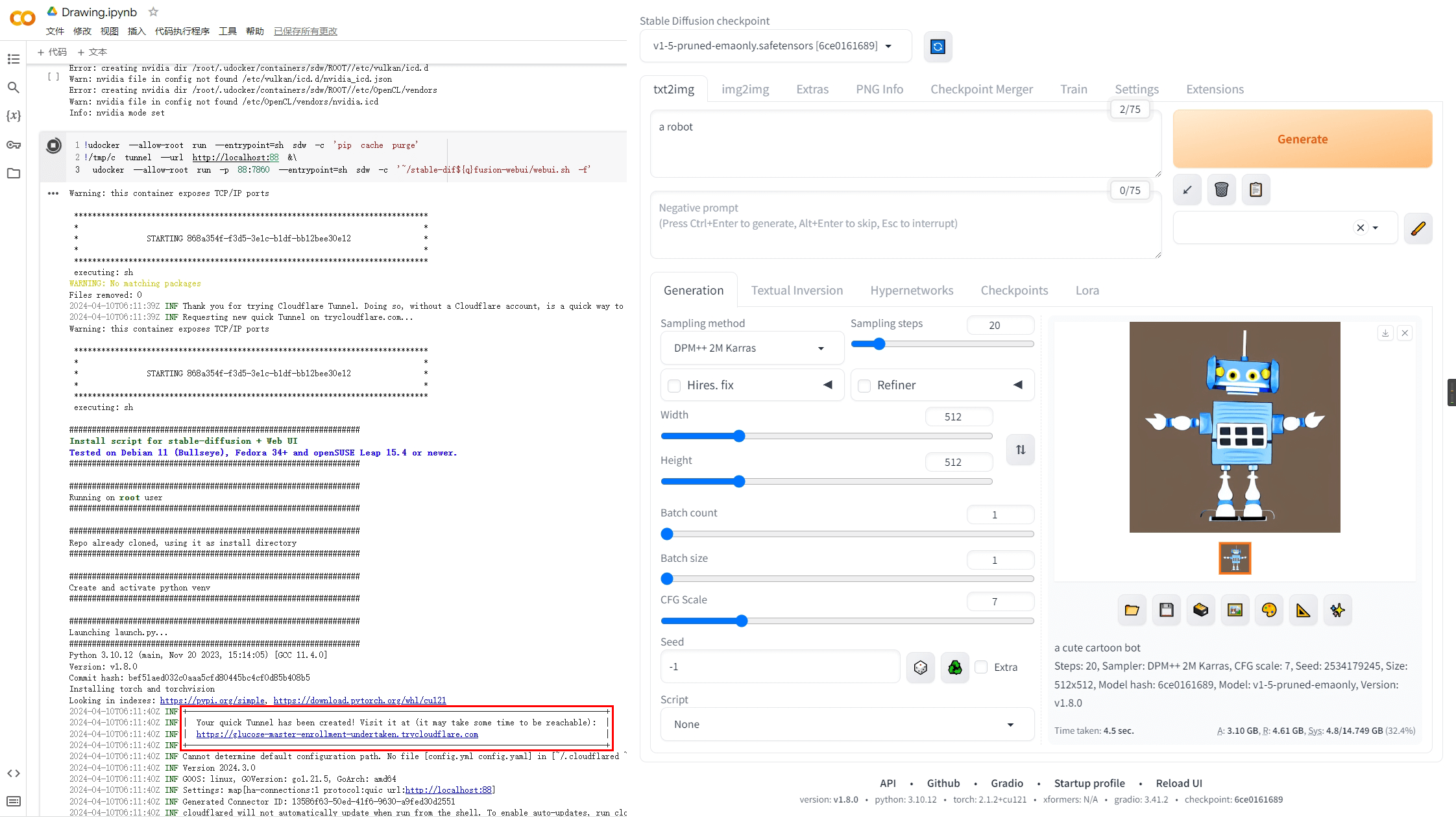
代码解释:
- 首先下载 cloudflared 用于最后建立隧道,因为镜像默认
--share 启动会造成环境崩溃。
- 接着是 udocker 替代 docker。由于环境限制,docker 无法在 colab/kaggle 中启动。
q 没有赋值,所以 ${q} 会被系统忽略,这里是用来绕过关键字检测。webui.sh -f 是允许 root 身份启动。- 以上代码分为两个 cell。启动 webui 会 pip 安装许多模块,为了清理缓存,可以在完全启动后停止再重启第二个 cell(约省 2G 多)。
- 因为是在容器内运行,所以外部应该可以删掉很多东西,给模型腾空间,具体哪些可以删晚些时候再研究。
不推荐使用 kaggle 的理由:
- stable diffusion webui 不支持多显卡,用 kaggle 纯属浪费。
- kaggle 会封杀 NSFW 图片,可能会实时炸号。
- kaggle 磁盘上限是以写入量计算,不方便删除切换模型。
最近 wordpress 自动升级到 6.5,然后后台就登录不了了。页面提示,需要数据库支持 MySQL≥5.5.5。
我并没有使用 MySQL,而是使用 sqlite。显然,开发者根本没考虑这种情况。尝试了一下直接修改数据库和源码,没能绕过检测。于是我通过覆盖降级了 wordpress,然后备份了一下数据重装。
中途换 sqlite 是因为机器磁盘有点小,而 MySQL 本身又挺大的。现在万不得已只好换回来。
教训就是,不要用原生不支持的特性,不知道什么时候就会遇到灾难。
我本地使用的 Windows 版只有 100M,而 linux 上居然有 1G。考虑到磁盘还是捉襟见肘,我打算研究下 MySQL 目录。
简而言之,我删除了 mysql-test,然后对 bin 目录和 lib 整个 upx --lzma --best *,最后只剩 101MB。
之后,我又删除了 nginx/src,再次回收几百 MB,只剩 14MB。
发现一个有意思的网站:station307.com
该网站用于两台机器间传输文件,只需要 wget 或 curl 即可。流式传输,而非临时网盘。
接收端输入 wget 命令,在输出中有一行随机生成的 web.url,在浏览器中打开这个地址,选文件发送即可。也可以不经过浏览器直接 post 数据过去。
这有什么好处呢?有时环境比较简单,可能没有 server 或者 ssh 权限,典型的如 kaggle,有了这个网站就可以很方便地发送本地文件。
最近还遇到的一个场景是,目标机器只能 ipv6 访问,正好手上的网络不支持,也用这个网站完成了快速分享。
一个很特殊的需求。 有一些上游的 APK 包,这些包都有固定的 url。上游升级 APK 时会覆盖原文件,我需要监控它们的版本号以更新到数据库。 有时候,一些 APK 包会特别大,例如游戏,动辄上 G。所以需要一些办法,不下载整个 APK 来提取信息。
脚本如下:
@echo off
goto :_Preparation
1. Install remotezip:
`pip install remotezip`
2. Download aapt2:
`remotezip https://dl.google.com/dl/android/maven2/com/android/tools/build/aapt2/8.3.1-10880808/aapt2-8.3.1-10880808-windows.jar aapt2.exe`
:_Preparation
set /p name="APK url: "
remotezip "%name%" AndroidManifest.xml 1>nul
zip -0 AM.zip AndroidManifest.xml 1>nul
aapt2 d badging AM.zip 2>nul|grep package| awk -F "'" "{print $6}{print $4}
del AM.zip AndroidManifest.xml
原理很简单,就是通过 remotezip 提取包内的 AndroidManifest.xml,将其打包进空的 zip,最后通过 aapt 解析。
之前写了一个在 Colab 上通过 udocker 部署 zhu327/genmini-openai-proxy,最近发现还有更方便的方式。
直接将代理地址改为 https://gemini-openai-proxy.deno.dev 即可接入支持 OpenAI 的客户端。
这是利用了 zuisong/gemini-openai-proxy。上面是公共的,自己搭也很方便。在 deno.dev 新建一个 Playground,直接粘贴进去就部署完毕了,还可以更换二级域名或绑定自己的域名。
和 Colab 相比,好处自然是长期在线。这个项目还有个 CF 版本,不建议使用,因为 CF 会根据地区就近访问,可能会碰到 Google 地区限制。
如果要本地跑,首选还是 zhu327/genmini-openai-proxy。可以编译一个本地版本,UPX 可以压缩到 10M 左右,安全又便携。以下是通过 Colab 编译 Linux / Windows 版本的示例:
%cd /content
!wget -c https://go.dev/dl/go1.21.1.linux-amd64.tar.gz
!tar -xvf go1.21.1.linux-amd64.tar.gz
!chmod +x go/bin/go
!git clone https://github.com/zhu327/gemini-openai-proxy
%cd /content/gemini-openai-proxy
# compile binary for linux
!/content/go/bin/go build -o gemini main.go
# compile binary for windows
!CGO_ENABLED=0 GOOS=windows GOARCH=amd64 /content/go/bin/go build -o gemini.exe main.go
### compress with upx
# !wget https://github.com/upx/upx/releases/download/v4.2.2/upx-4.2.2-amd64_linux.tar.xz
# !tar xvf upx-*
# !chmod a+x upx-4.2.2-amd64_linux/upx
# !upx-4.2.2-amd64_linux/upx --ultra-brute ?? -o??
之所以不用客户端自带的 Gemini 模型,是因为接口默认带有审核,而客户端一般不支持设置相关参数。