一次简单的 webpack 验证探索
前阵子在通过 Fofa 收集信息,发现了 Fofa-hack 项目。
一开始这个项目是登录抓取,但后来 Fofa 改了规则,限制了免费用户的访问总数。
于是,项目改为抓取网页上的链接,一次只能抓 10 条,通过 after / before 语法抓取更多之后的页面。当每页提升到 20 条时,访问里会出现一个 sign 验证参数,一段时间内无人解决。
再后来,项目引入了 webdriver,还有 fuzz 来提升抓取量。
我不太了解前端,在研究了 Fofa 的网页以及查了一些资料后,得知是 webpack。然后稍微逆了一下。与其说是逆向,不如说网站本身也没做复杂的混淆,防君子不防小人吧。
首先,验证参数是 sign,所以搜索 sign:
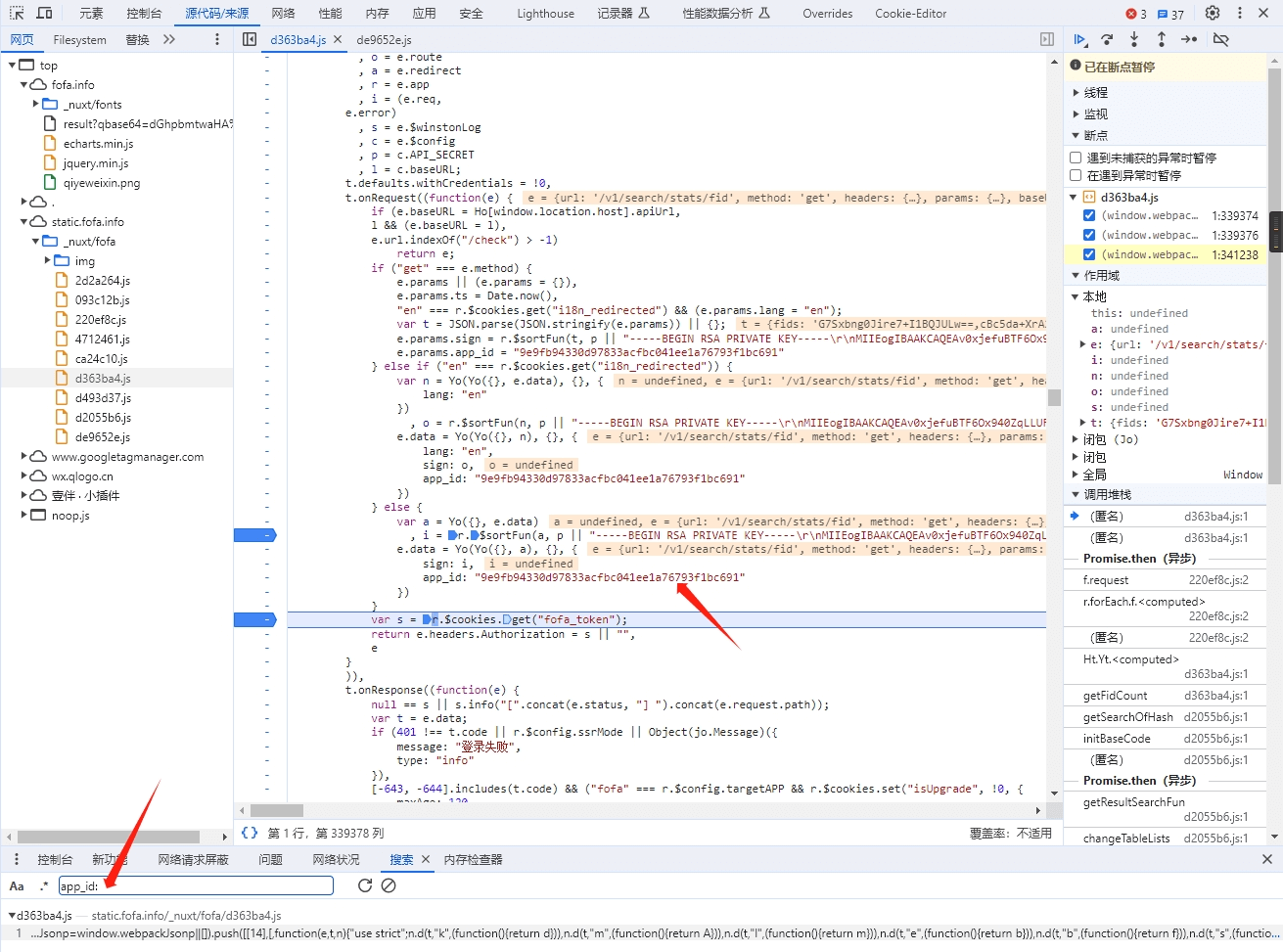
可以看到,这里跳到了一个 sortFun(),继续追踪这个方法。
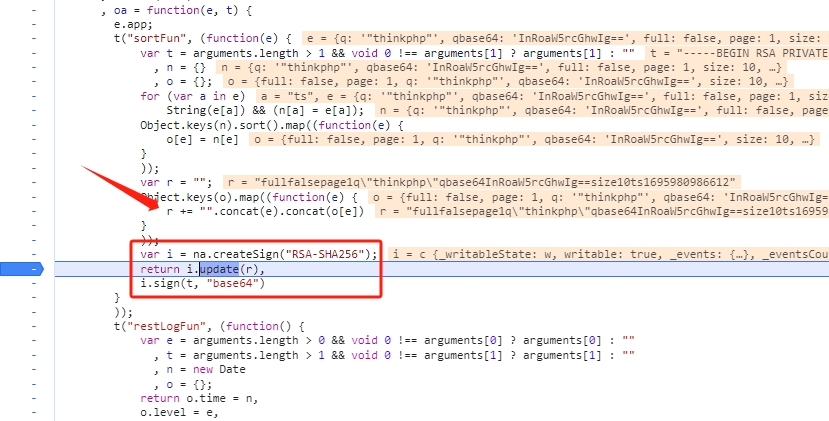
可以看到,sortFun() 实际是对 GET 参数的 key 进行 sort,然后拼接一下,最后为字符串 createSign()。
现在,Fofa-hack 已经支持了 sign 计算,并删掉了其他抓取方法。
python 版可以在项目内看到:简单的实现
这个接口一次可以抓取 100 条数据,配合 after / before 语法几乎可以抓全数据。
其他:
- 直到完成 PoC,才发现 app_id 是静态的,其实搜索 app_id 也能轻松定位到验证入口。
- 全网搜索 app_id 的值,发现已经有人研究过 sign 的算法,不过是用 Go 写的。
- 从前人的研究看,似乎还有 page 访问超过 100 页无法抓取的问题,不过我没有触碰到这个上限,具体情况不清楚。
- 这个接口除了可以突破网页版单页条目上限,也许还有其他网页不支持的特性,概率比较低,有空可以再看看。