Spaces 是 Huggingface 的一项免费服务,用于部署一些项目的 Demo。由于它支持 Docker,所以可玩性很高。建立一个 Space 后,在 Setting 中有一个 Dev Mode,提供 SSH Remote 到 Docker,实现方便地修改文件或执行一些交互式命令。
Dev Mode 是一个付费功能,我们当然不可能直接直接免费开启,不过可以用一些工具实现类似的功能。以及……随时触发 Huggingface 的制裁😅
首先,请看示例:DevMode-Demo。你可以直接查看 Files 了解它是怎么运作的,整体并不复杂。
我在 README.MD 中写了如何使用,你可以阅读本文或者查看项目中的介绍。
TL;DR 版本
Dumplicate 以上示例,PASSWORD 中填上你的连接密码,然后通过某个 Trojan 客户端连接到 Space。
以 v2rayN 为例,修改地址为你的 Space 域名(将 Space 设置为公开,然后在右上角 [...] - Embed this Space - Direct URL 中找到),协议 ws,路径 /control。
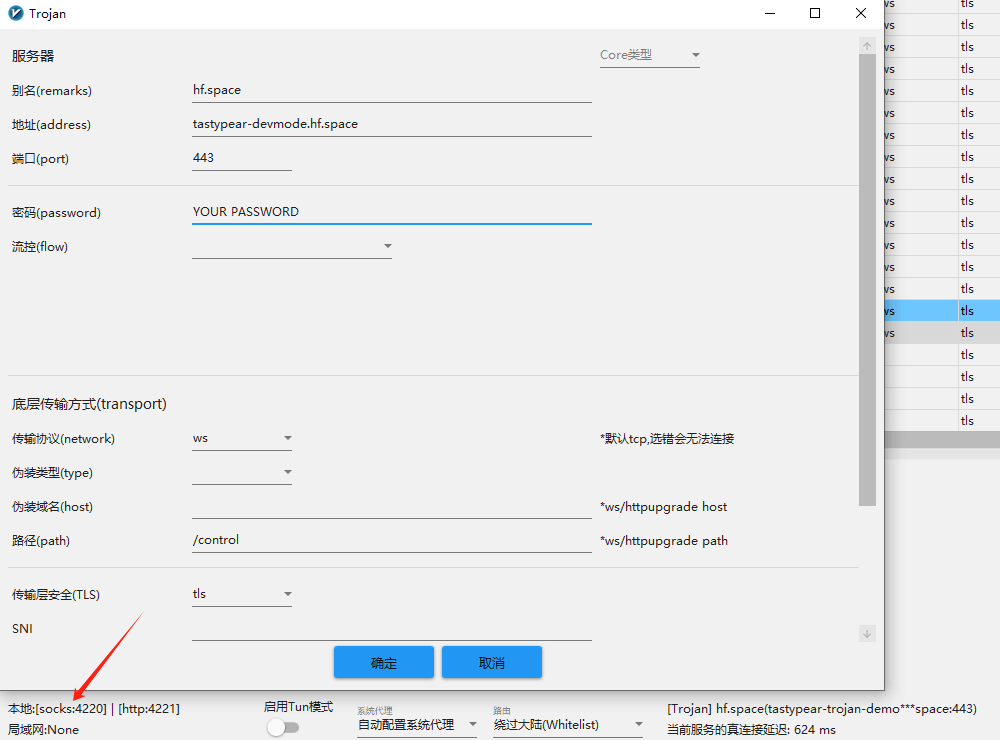
软件右下角有一个 socks:4220,这是本地 socks5 代理端口,通过它连接到主机。
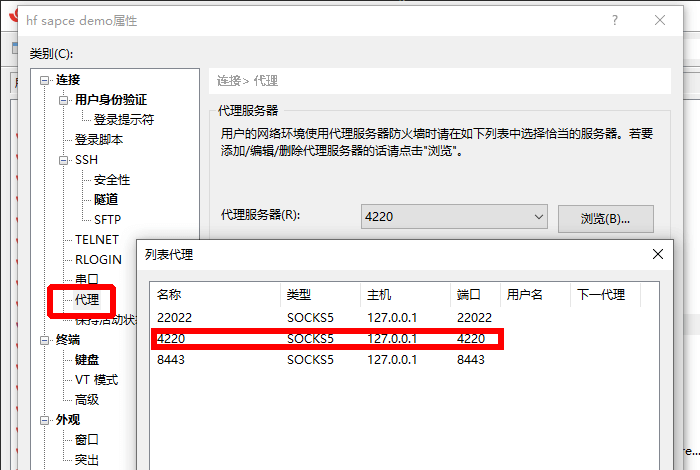
接下来使用 SSH 客户端,以 Xshell 为例,如图添加一个 4220 端口的 socks5 代理。
用户名 ubuntu,地址 localhost,端口 22022,无密码。之后就可以连接了。
更详细的介绍
接下来介绍一些 Spaces 的特性和使用注意事项,以及展示如何在命令行下配置。你可以将它视作进阶教程,也可以了解到一些在官方文档中没有提及的东西。
首先,一个免费 Space 有如下特性:
- 拥有一个独立分配的域名,无绑定域名功能。
- 每个账户的所有 Space 在同一时间段分配到 3 个 IP(CDN),会经常切换。
- 一个 Space 只能对外暴露一个端口,默认情况是 7860。
- 暴露的端口将被强制 tls 加密,只有基于 http 的服务能正常展示。
- 构建阶段是 root 权限,运行阶段是 uid=1000 的用户。su、sudo 是禁止的,getuid setuid 受限。
- 如果触发了某些禁制,可能会限流或与当前 Space 失联。这不针对账户,可以无限新建 Space。
- 12G 内存,275G 硬盘(启动后允许写入 50G 左右,超过后会强制回滚到初始状态)。
该项目要解决的问题是,如何在不触发禁制的情况下:
- 在没有 root 权限的情况下建立一个 ssh server
- 只通过一个端口,穿透到 Docker 内连接 ssh,且不影响首页展示。
我的具体方案是:Dropbear + Trojan + Nginx。
由于 trojanc 本身通过 http,套用 websocket 再经过 Space 强制加密后即可被外部连接。这样,我们就能穿透进 Docker,以 localhost 访问所有本地服务。vmess、vless 都支持,选 trojan 只是因为它比较方便设置密码。利用 nginx 的反向代理,将 trojan 与正常的首页区分开。这样就实现了一个端口既用于穿透又用于展示。
ssh 方面,传统的 openssh-server 是无法使用的。从 openssh 7.5 之后,程序已不再支持非 root 权限运行。常见的替代品是 tinyssh 和 dropbear,选择后者是因为它支持密码验证。
因为连接已经有 trojan 密码保护,所以就将 ssh 密码置空了。
本地连接 trojan,更方便的做法是使用 glider,而不是用 v2rayN。运行以下命令,注意密码最后有个@:
glider --listen socks5://:22022 -forward wss://域名.hf.sapce/control,trojanc://密码@
这样就在本地创建了一个 22022 端口的 socks5 代理。
然后,在 vscode 中安装 remote ssh 扩展,在配置主机中(即 .ssh/config)中填写以下配置之一进行连接:
Host Dev-Mode-Config-ncat
ProxyCommand "D:\…\ncat.exe" --proxy-type socks5 --proxy 127.0.0.1:22022 %h %p
HostName localhost
User ubuntu
Port 22022
Host Dev-Mode-Config-connect
ProxyCommand "D:\…\connect.exe" -S 127.0.0.1:22022 %h %p
HostName localhost
User ubuntu
Port 22022
以上是 Windows 的配置。ncat 是 netcat 的替代品,在 Nmap 包中提供。connect 则通常在 mingw64/bin 下,Git 工具通常都包含。可以用 everything 搜索看看,没有就用 ncat 配置。
Linux 也是类似,或者直接用 netcat。
如果中途重启了 Docker 导致证书变化,VSCode 会拒绝连接。此时删除本地 .ssh/known_hosts 即可重连。
最后,如果需要重启 nginx,尽量先通过其他隧道工具连接 ssh,不然启动失败会导致 trojan 断开,进而无法再连接到 docker。举例,我们通过 bore 建立一个反向隧道:
wget https://github.com/ekzhang/bore/releases/download/v0.5.1/bore-v0.5.1-x86_64-unknown-linux-musl.tar.gz
tar -xvf bore*.tar.gz && rm bore*.tar.gz && chmod +x bore
nohup ./bore local 22022 --to bore.pub &
# 查看端口
tail nohup.out
然后通过本地 ssh 客户端连接 [email protected]:port,在这个 session 中重启 nginx:
ps -ef | grep 'nginx' | grep -v grep | awk '{print $2}' | xargs -r kill -9 && nohup /usr/sbin/nginx -c /home/ubuntu/nginx.conf >/dev/null 2>&1 &
如果真的配置有误导致启动失败,仍可以通过新的新隧道挽救。如果你艺高人胆大,或者不在乎丢失当前 docker 数据,那么可以直接用以上命令重启 nginx。
如果想要自托管隧道,推荐用 wstunnel,它相比 bore 还额外支持 udp。
对了,不要用 cloudeflared 建立隧道,这会被制裁到 Space 强制断开。首页如果突然显示为 Preparing Space 则代表已经被制裁。重启 Space 是没用的,但可以 Dumplicate 当前 Space 继续工作。
还有,不要试图用 proot 虚拟 root。即使执行 proot --help,也会在几分钟后强制失联。
Space Benchmark:
ubuntu@localhost:~$ wget -qO- yabs.sh | bash
# ## ## ## ## ## ## ## ## ## ## ## ## ## ## ## ## ## #
# Yet-Another-Bench-Script #
# v2024-06-09 #
# https://github.com/masonr/yet-another-bench-script #
# ## ## ## ## ## ## ## ## ## ## ## ## ## ## ## ## ## #
Sun Jun 30 20:05:16 UTC 2024
Basic System Information:
---------------------------------
Uptime : 12 days, 2 hours, 51 minutes
Processor : Intel(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz
CPU cores : 16 @ 3499.737 MHz
AES-NI : ✔ Enabled
VM-x/AMD-V : ❌ Disabled
RAM : 123.8 GiB
Swap : 884.8 GiB
Disk : 1.7 TiB
Distro : Ubuntu 24.04 LTS
Kernel : 5.10.217-205.860.amzn2.x86_64
VM Type :
IPv4/IPv6 : ✔ Online / ❌ Offline
IPv4 Network Information:
---------------------------------
ISP : Amazon.com, Inc.
ASN : AS14618 Amazon.com, Inc.
Host : AWS EC2 (us-east-1)
Location : Ashburn, Virginia (VA)
Country : United States
fio Disk Speed Tests (Mixed R/W 50/50) (Partition overlay):
---------------------------------
Block Size | 4k (IOPS) | 64k (IOPS)
------ | --- ---- | ---- ----
Read | 6.15 MB/s (1.5k) | 65.86 MB/s (1.0k)
Write | 6.14 MB/s (1.5k) | 66.31 MB/s (1.0k)
Total | 12.29 MB/s (3.0k) | 132.18 MB/s (2.0k)
| |
Block Size | 512k (IOPS) | 1m (IOPS)
------ | --- ---- | ---- ----
Read | 63.65 MB/s (124) | 62.58 MB/s (61)
Write | 66.72 MB/s (130) | 67.04 MB/s (65)
Total | 130.38 MB/s (254) | 129.63 MB/s (126)
iperf3 Network Speed Tests (IPv4):
---------------------------------
Provider | Location (Link) | Send Speed | Recv Speed | Ping
----- | ----- | ---- | ---- | ----
Eranium | Amsterdam, NL (100G) | 1.72 Gbits/sec | 1.96 Gbits/sec | --
Uztelecom | Tashkent, UZ (10G) | 807 Mbits/sec | 931 Mbits/sec | --
Leaseweb | Singapore, SG (10G) | 620 Mbits/sec | 630 Mbits/sec | --
Clouvider | Los Angeles, CA, US (10G) | 1.84 Gbits/sec | 2.93 Gbits/sec | --
Leaseweb | NYC, NY, US (10G) | 3.16 Gbits/sec | 9.30 Gbits/sec | --
Edgoo | Sao Paulo, BR (1G) | 1.13 Gbits/sec | 1.39 Gbits/sec | --
Geekbench 6 Benchmark Test:
---------------------------------
Test | Value
|
Single Core | 1532
Multi Core | 1846
Full Test | https://browser.geekbench.com/v6/cpu/6734087
YABS completed in 13 min 26 sec